- 浏览: 2430478 次
- 性别:

- 来自: 上海
-

文章分类
最新评论
-
coosummer:
推荐使用http://buttoncssgenerator.c ...
几个漂亮的Button的CSS -
sws354:
多表连接的方式效率更低,几百条数据就能看出效果。
MySQL随机取数据最高效率的方法 -
lsj111:
用java实现如何做
PHP中利用mysql进行访问统计的思路和实现代码 -
check-枫叶:
您好!我现在也在弄google Maps,现在可以把2点之间的 ...
Google Maps API用法教程 -
nothingtalk:
博主,您好。
“所以我们接下来要介绍除去Gideon Ehr ...
排列组合算法1:生成全部有序列b
[转]IE到Mozilla迁移指南(把应用从IE迁移到Mozilla)[英文]
原始链接2:http://nexgenmedia.net/evang/iemozguide/
- Introduction
- What is Mozilla
- Mozilla Philosophy (standards compliant, etc)
- General Cross Browser Coding Tips
- Browser Detection the Right Way (capabilities VS browser specific checks)
- Abstracting Out Browser Differences
- DHTML
- DOM Differences
- document.all/global namespace VS document.getElementById
- Document Fragments
- Table of mappings from IE -> Standards/Mozilla (innerhtml)
- JavaScript Differences
- getYear() VS getFullYear
- execution - adding code to the end won't mean everything else has completed - use onload handlers
- window.open is async!
- CSS
- Units matter
- Image spacing
- Events
- IE event model VS Netscape/W3C model
- Table of mappings
- Rich Text Editing
- Differences between Designmode in IE and Mozilla
- XML
- whitespace differences in XML
- nodeType == 3 for text nodes
- XML Data Islands
- XSLT
- XSLT JS Interface
- XML Web Services
- XMLHttpRequest
- SOAP
- WSDL (?)
- Quirks VS Standard Modes
- Doctypes
- Furthur reading
- Books
- Mozilla.org
- DevEdge
Even though Web Standards exist, different browsers behave differently, sometimes even the same browser may behave so on different platforms.
Since different browsers sometimes use different apis for the same function, it is common to find multiple if() else() blocks throughout code to differentiate between browsers.
. . .
var elm;
if (ns4)
elm = document.layers["myID"];
else if (ie4)
elm = document.all["myID"];
The problem with doing this is that if a new browser is going to be supported, all these blocks need to be updated.
Therefore, when developing for multiple browsers, the easiest way to avoid the need to recode for a new browser is to abstract out functionality. Rather than multiple if() else() blocks throughout code, it is more efficient to take common tasks and abstract them out into their own functions. Not only does it make the code easier to read, it simplifies adding support for new clients.
var elm = getElmById("myID");
function getElmById(aID){
var rv = null;
if (isMozilla || isIE5)
rv = document.getElementById(aID)
else if (isNetscape4)
rv = document.layers[aID]
else if (isIE4)
rv = document.all[aID];
return rv;
}
However, there is still a issue with the code: the browser sniffing. Usually, browser sniffing is done via the useragent, such as:
Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.5) Gecko/20031016
While useragent sniffing provides detailed information on what browser is being used, code handling useragents can make mistaked when new versions of browsers arrive, thus requiring code changes.
If the type of browser doesn't matter (say non-supported browser have already been blocked from accessing the web application), it is better to sniff by browser capability.
Rather thanif (isMozilla || isIE5)it should be:
if (document.getElementById)
This would allow other browsers that support that command, like Opera or Safari, to work without any changes.
Useragent sniffing however does make sense when accuracy is important, such as verifying that a browser meets the version requirements of the web application or to workaround a bug in a certain version.
JavaScript allows inline conditional statements, which can help readability of code:
var foo = (condition) ? conditionIsTrue : conditionIsFalse;
For example, to retrieve an element:
function getElement(aID){
var rv = (document.getElementById) ? document.getElementById(aID) : document.all[aID];
return rv;
}
The Document Object Model (DOM) is the tree structure holding the elements inside the document. DHTML's biggest use is to modify the DOM by JavaScript, and the most often used task is to get a reference to an element.
The cross-browser way to get an reference to an element is via document.getElementById(aID). This works in IE5.5+ and Mozilla-based browsers, and is part of the DOM Level 1 specification.
Mozilla does not support accessing an element via document.elementName or even just via its name, which Internet Explorer does. Mozilla also does not support the Netscape 4 document.layers method and Internet Explorer's document.all.
It is also sometimes needed to get references to all elements with the same tagname, and in Mozilla, the DOM Level 1 getElementsByTagName() is the way to do so It returns in JavaScript an array, and can be called on the document element or other nodes to access only their subtree. To get an array of all elements in the DOM tree, getElementsByTagName(*) can be used.
One common use of these methods is to move an element to a certain position and toggling its visibility (menus, animations). Netscape 4 used the <layer> tag, which mozilla does not support. For Mozilla, the <div> tag is used, as does IE.
Mozilla supports the W3C DOM standard way of traversing the DOM tree. Children of an node can be accessed via node.childeNodes, which returns an array. Other methods available are firstChild and lastChild.
Nodes can access their parents via node.parentNode. Nodes can also acces their siblings via the node.nextSibling and node.previousSibling.
Mozilla supports the legacy methods for adding content into the DOM dynamically, such as document.write, document.open and document.close.
Mozilla also supports Internet Explorer's InnerHTML method, which can be called on almost any node. It does not however, support OuterHTML and innerText.
Internet Explorer has several content manipulation methods that are non-standard and not supported in Mozilla, such as retrieving the value, inserting text or inserting elements adjacent to an node such as getAdjacentElement and insertAdjacentHTML. Below is the chart of the W3C standard and Mozilla support ways of manipulation content, all of which are mehotds of any DOM node:
| appendChild( aNode ) | Creates a new child node. Returns a reference to the new child node. |
| cloneNode( aDeep ) | Makes a copy of the node it is called on and returns the copy. If aDeep is true, it recursively clones the subtree as well. |
| createElement( aTagName ) | Creates and returns a new, parentless DOM node of the type specified by aTagName. |
| createTextNode( aTextValue ) | Creates and returns a new, parentless DOM textnode with the data value specified by aTextValue. |
| insertBefore( aNewNode, aChildNode ) | Inserts aNewNode before aChildNode, which must be a child of the current node. |
| removeChild( aChildNode ) | Removes aChildNode and returns a reference to it. |
| replaceChild( aNewNode, aChildNode ) | Replaces aChildNode with aNewNode and returns a reference to the removed child node. |
For performance reasons, it can be usefull to create documents in memory, rather than working on the existing document's DOM. In DOM Level 1 Core, document fragments were introduced. They are "lightweight" documents, as they contain a subset of a normal document's interfaces. For example, getElementById does not exit, but appendChild does. Document fragments are also easily added to existing documents.
In Mozilla, document fragments are created via document.createDocumentFragment(), which returns an empty document fragment.
Internet Explorer's implementation of document fragments however does not comply with the W3C standard, and simply returns a full document.
width/height of an element, offsetWidth for exp.
Most differences between Mozilla and Internet Explorer are due to the DOM interfaces exposed to JavaScript. There are very few core JavaScript differences, and issues encountered are often timing related.
The only Date difference is the getYear method. In Mozilla, per the specification, it is not Y2k compliant, and running new Date().getYear() in 2004 will return "104". Per the ECMA specification, getYear returns the year minus 1900, originally meant to return "98" for 1998. getYear was deprecated in ECMAScript v3 and replced with getFullYear().
Different browsers execute JavaScript differently. For example, the following code:
...
<div id="foo">Loading...</div>
<script>
document.getElementById("foo").innerHTML = "Done.";
</script>
assumes that the div node exists already in the DOM by the time the script block gets executed. This is however not garantueed. To be sure that all elements exist, it is best to use the onload event handler on the <body> tag.
<body onload="doFinish()">
<div id="foo">Loading...</div>
<script>
function doFinish(){
document.getElementById("foo").innerHTML = "Done.";
}
</script>
...
Such timing-related issues are also hardware related - slower systems can reveal bugs that faster systems hide. One concrete example is window.open, which opens a new window.
<script>
function doOpenWindow(){
var myWindow = window.open("about:blank");
myWindow.location.href = "http://www.ibm.com";
}
</script>
The problem with the code is that window.open is asyncronous - it does not block the JavaScript execution until the window has finished loading.
Mozilla provides several ways to debug JavaScript related issues. The first tool is the built-in JavaScript console, where errors and warnings are logged. It can be opened by going to Tools -> Web Development -> JavaScript Console.
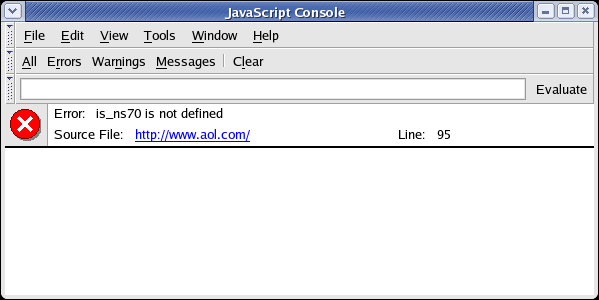
The JavaScript console can show the full log list, or just errors/warnings/messages. The error message in the screenshot says that at aol.com, line 95 tries to access an undefined variable called is_ns70. Clicking on the link will open Mozilla's internal view source window with the offending line highlighted.
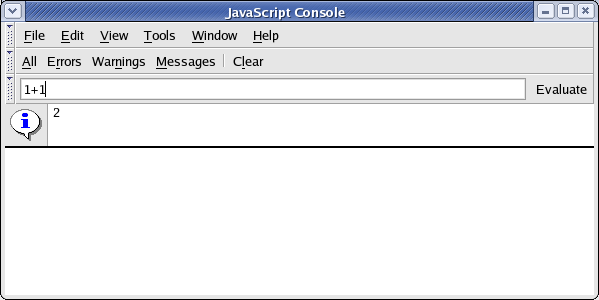
The console also allows for evaluating JavaScript. Typing in 1+1 into the input field and pressing the "Evaluate" button will evaluate the entered JavaScript syntax.
Mozilla's JavaScript engine has built in support for debugging, and thus can provide powerfull tools for JavaScript developers. The Mozilla JavaScript Debugger (called Venkman) is a powerfull, cross platform JavaScript debugger that integrates with Mozilla. It is usually bundled with Mozilla releases and can be found in Tools -> Web Development -> JavaScript Debugger. It can be downloaded and installed from http://www.mozilla.org/projects/venkman/. Tutorials can be found at the development page, located at http://www.hacksrus.com/~ginda/venkman/.
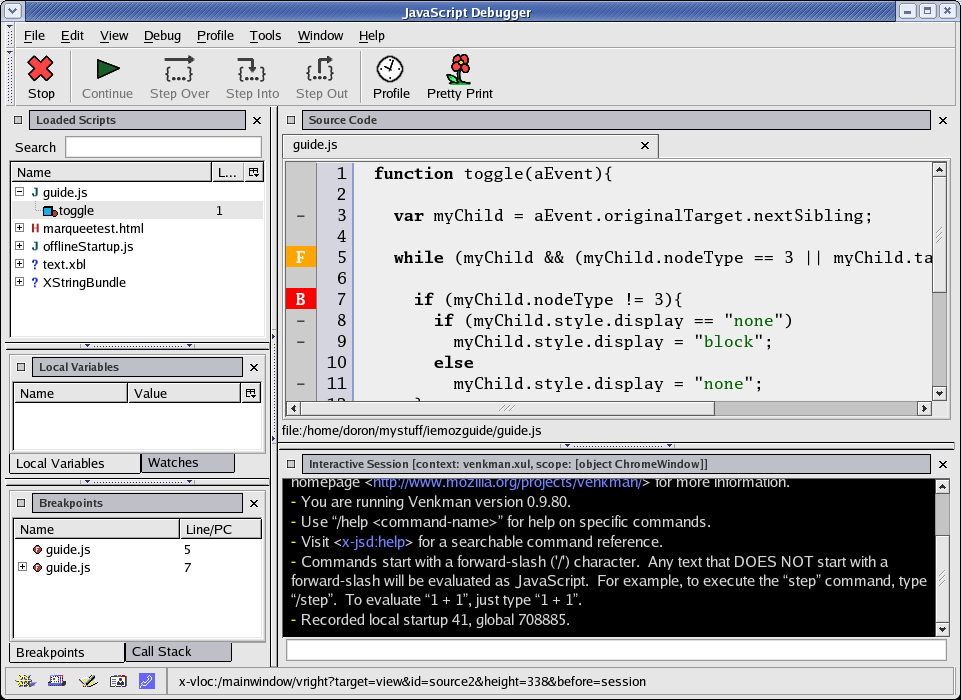
The JavaScript debugger can debug JavaScript running in the Mozilla browser window. It supports such standard debugging features such as breakpoint management, call stack inspection, and variable/object inspection. All features are accessible via the User Interface or via the debugger's interactive console. The console also allows to execute arbitrary JavaScript in the same scope as the JavaScript currently being debugged.
Events is one of the few areas where Mozilla and Internet Explorer are nearly completly different.
The Mozilla event model is completly different from the Internet Explorer model. It follows the W3C and Netscape model.
In Internet Explorer, if a function is called from an event, itcan access the event object via window.event. In Mozilla, event handlers get passed an event object, and they must specifically pass it on to the function called via an argument. A cross-browser event handling example:
<div onclick="handleEvent(event)">Click me!</div>
<script>
function handleEvent(aEvent){
// if aEvent is null, means the IE event model, so get window.event.
var myEvent = aEvent ? aEvent : window.event;
}
</script>
The properties and functions the event object exposes are also often named differently between Mozilla and IE. A table can be found below:
| altKey | altKey | Boolean property which returns wether the alt key was pressed during the event. |
| cancelBubble | stopPropagation() | Used to stop the event from bubbling furthur. |
| clientX | clientX | The X coordinate of the event, in relation to the client area. |
| clientY | clientY | The Y coordinate of the event, in relation to the content window. |
| ctrlKey | ctrlKey | Boolean property which returns wether the ctrl key was pressed during the event. |
| fromElement | relatedTarget | For mouse events, this is the element that the mouse moved away from. |
| keyCode | keyCode | For keyboard events, this is a number representing the key that was pressed. Is 0 for mouse events. |
| returnValue | preventDefault() | Used to prevent the default action of the event from occuring. |
| screenX | screenX | The X coordinate of the event, in relation to the screen. |
| screenX | screenY | The Y coordinate of the event, in relation to the screen. |
| shiftKey | shiftKey | Boolean property which returns wether the shift key was pressed during the event. |
| srcElement | target | The element to which the event was originally dispatched. |
| toElement | relatedTarget | For mouse events, this is the element that the mouse moved towards. |
| type | type | Returns the name of the event. |
Mozilla supports two ways to attach events via JavaScript. The first way, supported by all browers is to set event properties directly on objects. To set an click event handler, a function reference is passed to the object's onclick property.
<div id="myDiv">Click me!</div>
<script>
function handleEvent(aEvent){
// if aEvent is null, means the IE event model, so get window.event.
var myEvent = aEvent ? aEvent : window.event;
}
function onPageLoad(){
document.getElementById("myDiv").onclick = handleEvent;
}
</script>
The W3C standard way of attaching listeners to DOM nodes is fully supported in Mozilla. The addEventListener() and removeEventListener() methods are used, and have the benefit of being able to set multiple listeners for the same event type. Both methods require three parameters - the event type, a function reference and a boolean denoting if the listener should catch events in their capture phase. If the boolean is set to false, it will only catch bubbling events. W3C events have three "phases" - capturing, at target and bubbling, and every event object has a eventPhase attribute indicating the phase numerically (0 indexed). Every time an event is triggered, the event starts at the outermost element of the DOM, the element at top of the DOM tree. It then walks the DOM using the most direct route towards the target, which is called the capturing phase. After arriving at the target, it walks up the DOM tree back to the outermost node, called bubbling. Internet Explorer's event model only has the bubbling phase, therefore setting the third parameter to false will result in IE-like behavior.
<div id="myDiv">Click me!</div>
<script>
function handleEvent(aEvent){
// if aEvent is null, means the IE event model, so get window.event.
var myEvent = aEvent ? aEvent : window.event;
}
function onPageLoad(){
document.getElementById("myDiv").addEventListener("click", handleEvent, false);
}
</script>
One advantage of addEventListener() and removeEventListener() over setting properties is that one can have multiple event listeners for the same event, each calling another function. Due to this, removing an event listener requires all three parameters to be the same as the ones used when adding the listener.
Mozilla does not support Internet Explorer's method of converting <script> tags into event handlers, which extends <script> with for and event attributes. It also does not support the attachEvent and detachEvent methods. Instead, the addEventListener and removeEventListener methods should be used. Internet Explorer does not support the W3C Events specification at all.
| attachEvent(aEventType, aFunctionReference) | addEventListener(aEventType, aFunctionReference, aUseCapture) | Adds an event listener to an DOM element. |
| detachEvent(aEventType, aFunctionReference) | removeEventListener(aEventType, aFunctionReference, aUseCapture) | Removes an event listener to an DOM element. |
Mozilla has the strongest support for Cascade Style Sheets (CSS) compared to all other browsers, including most of CSS1, CSS2 and parts of CSS3.
The most common CSS-related issue is that CSS definitions inside referenced CSS files are not applied. This is usually due to the server sending the wrong mimetype for the CSS file. The CSS specification states that CSS files should be served with the text/css mimetype. Mozilla will respect this and only load CSS files with that mimetype if the webpage is in strict standards mode. Web pages are considered in strict standards mode when they start with a strict doctype. The solution is to make the server send the right mimetype or to remove the doctype. More about doctypes in the next section.
A lot of web applications do not use units with their CSS, especially when JavaScript is used to set the CSS. Mozilla is tolerant of this, as long as the page is not rendered in strict mode. If the page is in strict standards mode, and no units are used, then the command is ignored.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html>
<body>
<div style="width:40px; border:1px solid black;">Click me!</div> // works in strict mode
<div style="width:40; border:1px solid black;">Click me!</div> // will fail in strict mode
</body>
</html>
In the above example, since there is a strict doctype, the page is rendered in strict standards mode. The first div will have a width of 40px, since it uses units, but the second div won't get a width, and thus will default to 100% width. The same would apply if the width were set via JavaScript.
Since Mozilla supports the CSS standards, it also supports the CSS DOM standard for setting CSS via JavaScript. An element's CSS rules can be accessed, removed and changed via the element's style member.
<div id="myDiv" border:1px solid black;">Click me!</div>
<script>
var myElm = document.getElementById("myDiv");
myElm.style.width = "40px";
</script>
Every CSS attribute can be reached that way. Again, if the web page is in strict mode, setting a unit is required, else the command will be ignored.
In Mozilla and other browsers, when querying a value, say via .style.width, the returned value will contain the unit, meaning a string is returned. The string can be converted into a number via parseFloat("40px").
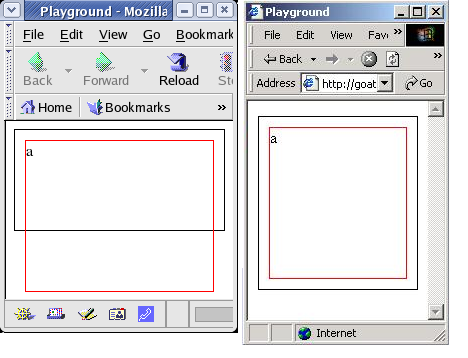
CSS added the notion of overflow, which allows one to define how overflow should be handled. An example of overflow would be a div with a specified height, and its contents are taller than that height. The CSS standard defines that if this happens and no overflow behavior is set, the contents of the div will overflow. However, Internet Explorer does not comply with this, and will expand the div beyone its set height inorder to hold the contents. Below is an example:
<div style="height:100px; border: 1px solid black;">
<div style="height:150px; border: 1px solid red; margin:10px;">a</div>
</div>
As can be seen in the below screenshots, Mozilla acts like the standard specifies and the inner div overflows to the bottom. If the IE behavior is desired, simply don't specify a height on the outer element.
Older legacy browsers such as versions 4 of Netscape and IE had so called quirks in their rendering under certain conditions. While Mozilla aims to be a standards compliant browser, in order to support older webpages written to the quirky behaviors, Mozilla has 3 modes when it comes to rendering a webpage, and the content and way the page is delivered to the browser determine which mode is used. To find out what mode a page is rendered in, View -> Page Info (or ctrl-i) in Mozilla will list the Render Mode mozilla is using.
Doctypes (short for document type declaration) look like this:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
The section in blue is called the public identifier, the green part is the system identifier, which is a URI.
Standards mode is the most strict rendering mode - it will render pages per the W3C HTML and CSS specifications and will not support any quirks at all.
Standards mode is used for the following conditions:
- If a page is sent with an
text/xmlmimetype, or any other XML or XHTML mimetype - Any "DOCTYPE HTML SYSTEM" doctype (
<!DOCTYPE HTML SYSTEM "http://www.w3.org/TR/REC-html40/strict.dtd">for example), except for the IBM doctype - Unknown doctypes or doctypes without DTDs
Almost standards mode was introduced into Mozilla for one reason: a section in the CSS 2 specification breaks designs based on a precise layout of small images in table cells. Instead of forming one image to the user, each small image ends up with gap. An example is the IBM homepage:

Almost standards mode behaves almost exactly as standards mode does. It makes an exception though for image gap issue, as it occurs quite often that pages call themselves standards compliant, yet are hosed due to the image gap situation.
Standards mode is used for the following conditions:
- Any "loose" doctype (
<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN">,<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">for example) - The IBM doctype (
<!DOCTYPE html SYSTEM "http://www.ibm.com/data/dtd/v11/ibmxhtml1-transitional.dtd">)
Currently, the web is full of invalid HTML markup, as well as markup that only functions to do to bugs in browsers. The old Netscape browers, when they were the market leaders, had bugs. When Internet Explorer came, it mimicked those bugs so that it would work with content at that time. As newer browsers came, most of these original sins were kept for backwards compatability, usually called quirks. Mozilla supports many of these quirks in its quirks rendering mode. Note that due to these quirks, pages will render slower than if they were fully standards compliant. Most web pages will be rendered under this mode.
Quirks mode is used for the following conditions:
- No doctype is specified
- Doctypes without an system identifier (
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">for example)
List of Doctypes and what modes they cause
While Mozilla prides itself with being the most W3C standards compliant browser, it does support non-standard functionality if there is no W3C equivalent. innerHTML is one example, another is rich text editing.
Mozilla 1.3 introduced an implementation of Internet Explorer's designMode feature. Mozilla supports the designMode feature which turns an HTML document into an rich-text editor field. Once turned into the editor, commands can be run on the document via the execCommand command. Mozilla does not support IE's contentEditable attribute for making any widget editable.
The best way of adding an richt-text editor is by using an iframe and making that become the rich text editor.
Since iframes are the most convinient ways of having part of a page be a rich text editor, one needs to be able to access the document object of the iframe. Mozilla supports the W3C standard of accessing it via IFrameElm.contentDocument, while IE requires you to go via document.frames["name"] and then access the result's document.
function getIFrameDocument(aID){
var rv = null;
// if contentDocument exists, W3C compliant (Mozilla)
if (document.getElementById(aID).contentDocument){
rv = document.getElementById(aID).contentDocument;
} else {
// IE
rv = document.frames[aID].document;
}
return rv;
}
Another difference between Mozilla and Internet Explorer is the HTML that the rich text editor creates. Mozilla defaults to using CSS for the generated markup. However, Mozilla allows one to toggle between HTML and CSS mode using the useCSS execCommand and toggling it between true and false.
Mozilla (CSS):
<span style="color: blue;">Big Blue</span>
Mozilla (HTML):
<font color="blue">Big Blue</font>
Internet Explorer:
<FONT color="blue">Big Blue</FONT>
| bold | Toggles the bold attribute of the selection. | --- |
| createlink | Generates an HTML link from the selected text. | The URL to use for the link |
| delete | Deletes the selection | --- |
| fontname | Changes the font used in the selected text. | The font name to use (Arial for example) |
| fontsize | Changes the font size used in the selected text. | The font size to use |
| fontcolor | Changes the font color used in the selected text. | The color to use |
| indent | Indents the block where the caret is. | --- |
| inserthorizontalrule | Inserts an <hr> element at the position of the cursor. | --- |
| insertimage | Inserts an image at the position of the cursor. | URL of the image to use |
| insertorderedlist | Inserts an ordered list (<ol>) element at the position of the cursor. | --- |
| insertunorderedlist | Inserts an unordered list (<ul>) element at the position of the cursor. | --- |
| italic | Toggles the italicize attribute of the selection. | --- |
| justifycenter | Centers the content at the current line. | --- |
| justifyleft | Justifies the content at the current line to the left. | --- |
| justifyright | Justifies the content at the current line to the right. | --- |
| outdent | Outdents the block where the caret is. | --- |
| redo | Redoes the previously undo command. | --- |
| removeformat | Removes all formatting from the selection. | --- |
| selectall | Selects everything in the rich text editor. | --- |
| strikethrough | Toggles the strikethrough of the selected text. | --- |
| subscript | Converts the current selection into subscript. | --- |
| superscript | Converts the current selection into superscript. | --- |
| underline | Toggles the underline of the selected text. | --- |
| undo | Undoes the last executed command. | --- |
| unlink | Removes all link information from the selection. | --- |
| useCSS | Toggles the usage of CSS in the generated markup. | Boolean value |
Mozilla has strong support for XML and XML-related technologies such as XSLT and web services. It also supports some non-standard extensions such as XMLHttpRequest.
As with standard HTML, Mozilla supports the W3C XML DOM specification, which allows one to manipulate almost any aspect of an XML document. Differences between IE's XML DOM and Mozilla usually are caused by IE's non-standard behaviors lsited below:
The probably most comment difference is in the handling whitespace text nodes. Often when XML is generated, it contains whitespaces between XML nodes. In IE, when using XMLNode.childNodes[], it will not contain these whitespace nodes. In Mozilla, those nodes will be in the array.
XML:
<?xml version="1.0"?>
<myXMLdoc xmlns:myns="http://myfoo.com">
<myns:foo>bar</myns:foo>
</myXMLdoc>
JavaScript:
var myXMLDoc = getXMLDocument().documentElement;
alert(myXMLDoc.childNodes.length);
The first line of JavaScript loades the XML document and accesses the root element (myXMLDoc) by retrieving the documentElement. The second line simply alerts the number of child nodes. Per the W3C specification, the whitespaces and new lines get merged into 1 text node if the follow eachother, so for Mozilla, the myXMLdoc node has three children: first a text node containing a newline and two spaces, then the myns:foo node, and finally another text node with a new line. Internet Explorer however does not abide by this and will return "1" for the above code, namely only the myns:foo node. Therefore, in order to walk the child nodes and disregard text nodes, it is nessessary to distinguish such nodes.
Every node has a nodeType attribute representing the type of the node. For example, an element node has type 1, while a document node is of type 9. In order to disregard text nodes, one has to check for type's 3 (text node) and 8 (comment node).
XML:
<?xml version="1.0"?>
<myXMLdoc xmlns:myns="http://myfoo.com">
<myns:foo>bar</myns:foo>
</myXMLdoc>
JavaScript:
var myXMLDoc = getXMLDocument().documentElement;
var myChildren = myXMLDoc.childNodes;
for (var run = 0; run < myChildren.length; run++){
if ( (myChildren[run].nodeType != 3) && (myChildren[run].nodeType != 8) ){
// not a text or comment node
}
}
Internet Explorer has a non-standard feature called XML Data Islands. It allows the embedding of XML inside a HTML document using the non-standard HTML tag <xml>. Mozilla does not support XML Data Islands, and will handle them as unknown HTML tags. The same functionality could be achieved using XHTML, however since Internet Explorer's support for XHTML is weak, this is usually not a choice.
One cross-browser solution would be to use DOM parsers. DOM parsers parse a string that contains a serialzed XML document, and generate the document for the parsed XML. In Mozilla, the DOMParser class is used, which takes the serialized string and created an XML document out of it. In Internet Explorer, the same functionality can be achieved using ActiveX. A new Microsoft.XMLDOM is generated, and it has a loadXML method that can take in a string and generated a document from it. The following example shows how it can be done:
IE XML Data Island:
..
<xml id="xmldataisland">
<foo>bar</foo>
</xml>
Cross Browser Solution:
var xmlString = "<xml id=\"xmldataisland\"><foo>bar</foo></xml>";
var myDocument;
if (document.implementation.createDocument){
// Mozilla, create a new DOMParser
var parser = new DOMParser();
myDocument = parser.parseFromString(xmlString, "text/xml");
} else if (window.ActiveXObject){
// IE, create a new XML document using ActiveX
// and use loadXML as a DOM parser.
myDocument = new ActiveXObject("Microsoft.XMLDOM")
myDocument.async="false";
myDocument.loadXML(xmlString);
}
Internet Exploer allows sending and retrieving of XML files using MSXML's XMLHTTP class, which is instantiated via ActiveX using new ActiveXObject("Msxml2.XMLHTTP") or new ActiveXObject("Microsoft.XMLHTTP"). Since there used to be no standard method of doing this, Mozilla provides the same functionality in the global JavaScript XMLHttpRequest object. It generates asynchronous requests by default.
After instantiating it using new XMLHttpRequest(). the open method is used to specifiy what type of request (GET or POST) should be used, which file to load and if it should be asynchronous or not. If the call is asynchronous, then the onload member should be given a function reference which will be called once the request has completed.
Synchronous request:
var myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "data.xml", false);
myXMLHTTPRequest.send(null);
var myXMLDocument = myXMLHTTPRequest.responseXML;
Asynchronous request:
var myXMLHTTPRequest;
function xmlLoaded(){
var myXMLDocument = myXMLHTTPRequest.responseXML;
}
function loadXML(){
myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "data.xml", true);
myXMLHTTPRequest.onload = xmlLoaded;
myXMLHTTPRequest.send(null);
}
Mozilla supports the 1.0 specification of XSL Transformations (XSLT). Mozilla also allows JavaScript to perform XSLT transformations as well as running XPATH on an document.
Mozilla requires that the XML and XSLT file holding the stylesheet be sent with an XML mimetype (text/xml or application/xml). This is the most common reason for XSLT not running in Mozilla, as Internet Explorer is not as strict.
Internet Explorer 5.0 and 5.5 supported the working draft of XSLT, which is substantially different than the final 1.0 recommendation. The easiest way to distinguish what version an XSLT file was written against is to look at the namespace. The namespace for the 1.0 recomendation is http://www.w3.org/1999/XSL/Transform, while the working draft used http://www.w3.org/TR/WD-xsl. Internet Explorer 6 supports the working draft for backwards compatability, but Mozilla does not support the working draft, only the final recommendation.
If distinguishing the browser is required from within XSLT, the "xsl:vendor" system property can be queried. Mozilla's XSLT engine will report itself as "Transformiix", and Internet Explorer will return "Microsoft".
<xsl:if test="system-property('xsl:vendor') = 'Transformiix'">
<!-- Mozilla specific markup -->
</xsl:if>
<xsl:if test="system-property('xsl:vendor') = 'Microsoft'">
<!-- IE specific markup -->
</xsl:if>
Mozilla also provides JavaScript interfaces for XSLT, allowing a web site to complete XSLT transformation in memory. This is done using the global XSLTProcessor JavaScript object. XSLTProcessor requires one to load the XML and XSLT files, as it requires their DOM documents. The XSLT document is imported by the XSLTProcessor, and allows manipulation of XSLT parameters. XSLTProcessor can generate a standalone document using transformToDocument(), or can create a Document Fragment using transformToFragment() which can be easily appened into another DOM document. Below is an example:
var xslStylesheet;
var xsltProcessor = new XSLTProcessor();
// load the xslt file, example1.xsl
var myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xsl", false);
myXMLHTTPRequest.send(null);
// get the XML document and import it
xslStylesheet = myXMLHTTPRequest.responseXML;
xsltProcessor.importStylesheet(xslStylesheet);
// load the xml file, example1.xml
myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xml", false);
myXMLHTTPRequest.send(null);
var xmlSource = myXMLHTTPRequest.responseXML;
var resultDocument = xsltProcessor.transformToDocument(xmlSource);
After creating an XSLTProcessor, the XSLT file is loaded using XMLHttpRequest. Its responseXML member contains the XML document of the XSLT file, which is passed to importStylesheet. XMLHttpRequest is then used again to load the source XML document that is to be transformed, which is then passed to XSLTProcessor's transformToDocument method. Below is a list of XSLTProcessor's methods:
| void importStylesheet(Node styleSheet) | Imports the XSLT stylesheet. The styleSheet argument is the root node of an XSLT stylesheet's DOM document. |
| DocumentFragment transformToFragment(Node source, Document owner) | Transforms the Node source by applying the stylesheet imported using the importStylesheet method and generates a DocumentFragment. owner specifies what DOM document the DocumentFragment should belong to, making it appendable to that DOM document. |
| Document transformToDocument(Node source) | Transforms the Node source by applying the stylesheet imported using the importStylesheet method and returns a standalone DOM document. |
| void setParameter(String namespaceURI, String localName, Variant value) | Sets a parameter in the imported XSLT stylesheet. |
| Variant getParameter(String namespaceURI, String localName) | Gets the value of an parameter in the imported XSLT stylesheet. |
| void removeParameter(String namespaceURI, String localName) | Removes all set parameters from the imported XSLT stylesheet and makes them default to the XSLT-defined defaults. |
| void clearParameters() | Removes all set parameters and sets them to defaults specified in the XSLT stylesheet. |
| void reset() | Removes all parameters and stylesheets. |


发表评论

相关推荐
使特定于 Internet Explorer 的 Web 应用程序在 ...本文讨论了将应用程序迁移到基于开源 Mozilla 浏览器上时的常见问题。首先讨论跨浏览器开发的基本技术,然后介绍克服 Mozilla 和 Internet Explorer 之间差异的策略。
foundation.mozilla.org 目录 如何使用Docker设置开发环境 要求: (macOS和Windows)或和 ... 安装将花费几分钟:您需要从Docker Hub下载映像,安装JS和Python依赖项,创建伪造数据,迁移数据库等。 完成后,运行do
火狐浏览器英文全称Mozilla Firefox,是一个开源网页浏览器,使用Gecko引擎(非ie内核),支持多种操作系统如Windows、Mac和linux。 火狐浏览器for linux v52.0.2更新日志: 全新的定制模式让自定义你的网络体验更...
Funambol Mozilla 插件是一个 Mozilla 插件,允许在 Mozilla 和 Funambol 服务器之间同步日历和地址簿。 此项目已迁移到新的 Funambol Forge:https://mozilla-plugin.forge.funambol.org/
GITHUB_DEST_REPO是将问题迁移到的目标存储库,例如mozilla/mozilla-learning 。 MIGRATION_DELAY_SECONDS是迁移每个问题之前要等待的秒数(仅在迁移多个问题时有效)。 默认值为5。为避免。 快速开始 运行npm ...
在Linux上,在~/.mozilla/firefox/找到您的配置文件目录。 配置文件目录通常以随机字符串开头,以.default结束。 您也可以从about:support页面获取路径。 找到后,导航到目录并运行 git clone ...
该项目已迁移到GitLab : ://gitlab.com/ivanruvalcaba/BehindTheOverlayRevival(#GithubExodus) 。重叠式广告的背后-Mozilla Firefox WebExtension- 该项目是附加组件的一个分支,被移植为Mozilla Firefox ...
在迁移到Python 3期间,master分支不稳定。 如果必须使用Python 2,请尝试使用 。 如果遇到问题,请尝试最新或检查未解决的问题以进行后续工作。 关于 Firefox Decrypt是从Mozilla(Fire / Water)fox:trade_mark...
正在进行的工作:迁移到WebExtensions(Mozilla的新API)。 在Linux / Mac OS上进行开发。 否则,如果克隆到不支持符号链接的文件系统,请当心附加组件通过符号链接共享shared / old_addon_versions.js。 (Selenium...
随着H5的兴起,传统的C/S构架产品逐步迁移到B/S架构上,但是H5的版本演进一直没能很好的解决实时视频播放的问题,从HLS到WebRtc 再到 Wasm 都伴随着它的问题, HLS延迟大满足不了实时流性要求; WebRTC 复杂以及更...
import-mailbox-to-gmail 是 Gmail 的邮件导入工具,可以把 .mbox 文件导入到 to Google Apps for Work。...如果你想从 Mozilla Thunderbird 迁移到 Gmail,可以尝试 mail-importer。 标签:import
是对旧版软件的重写 这是Mozilla Firefox的扩展程序,但在Mozilla Firefox迁移到WebExtensions时,其开发在2016年左右停止。 DownZemAll! 是Windows,MacOS和Linux的独立下载管理器。 它旨在与最新版本的Mozilla...
如果您使用的是Buildhub,请迁移到 。 细节 Buildhub旨在提供包含发行和构建的全面信息的公共数据库。 执照 发展历程 安装Docker 运行测试: make test 要检查make lintcheck代码: make lintcheck 持续集成 ...
我们希望通过迁移到基于Nodejs的环境中,Pencil源代码可以使所有其他开发人员更容易使用。 Mozilla XULRunner已过时的事实也是这一趋势的原因。 引入了一种基于zip的新文件格式,以支持大型文档并更好地嵌入外部位...
该项目已迁移到GitLab : ://gitlab.com/ivanruvalcaba/multi-keywords-highlighter(#GithubExodus) 。多关键字荧光笔在您访问的任何网页上突出显示给定的关键字。产品特点Multi-Keywords Highlighter是Firefox ...
它主要是为Mozilla Firefox和AMO上的附加插件( )构建的。 此插件应可迁移至Chrome / Opera / Microsoft Edge插件。 但是由于不允许在这些商店免费发布插件,所以我看不到自己向公众发布这种分支的方法。 但是,您...
在我们迁移到社区门户之前,此存储库保存了所有旧的reps.mozilla.org数据。 它提供带有所有代表列表的index.html,并为每个代表生成一个HTML页面,包括其公共资料数据,事件和活动报告。 设置 首先安装并克隆此存储...
4.1 部署和迁移成本 25 4.2 人员和培训成本 26 4.3 管理维护和技术支持成本 27 4.4 风险控制成本 28 第2篇 使用开源软件 第5章 正确使用开源软件 32 5.1 管理体制 32 5.2 法律风险 33 5.2.1 法律因素之著作权 34 ...
Mozilla 文档关于 Web 开发基础知识 + 服务器端深入 完毕 行进 设置 Django 后端 实现了一个外部 API 以查看后端设置是否适用于 数据结构 在 AlgoExpert 上练习题 建立本地发展 解决了 设置基本分页(Featured 最终...
AuditKube 针对Amazon,Google和Azure的面向合规性的... 我们帮助企业迁移到Kubernetes所以如果您需要帮助! 执照 此源代码表受Mozilla公共许可证v。2.0条款的约束。 如果未随该文件分发MPL的副本,则可以从获得一个。